

L'Estimation Statistique
Le problème traité dans ce chapitre est le suivant: on se trouve en présence d'un échantillon et l'on cherche à déterminer explicitement la loi de probabilité définissant la population de référence dont ces observations peuvent être considérées comme issues. Nous admettrons spécifiée la forme analytique de la loi de probabilité que suivent les observations. Dans ces conditions, on se trouve conduit à estimer les paramètres θ1, θ2,... de la loi de probabilité p(x ; θ1, θ2, ...) à partir de l'échantillon observé x1, x2, ..., xn, c'est à dire à tirer de cet échantillon une information concernant la valeur des paramètres inconnus. Il s'agit de plus de pouvoir émettre un jugement sur la qualité de cette information
1 - Estimateur et Intervalle de Confiance
Loi des Grands Nombres
Considérons une suite de variables aléatoires X1, ..., Xi, ..., Xn indépendantes, et ayant toutes la même loi de probabilité qu’une variable aléatoire X. La loi de probabilité de X peut être quelconque de moyenne E(X) = μ et de variance σ²
Soit Mn = 1/n (X1 + ... + Xi + ... + Xn) la moyenne arithmétique des variables X1, ..., Xi, ..., Xn.
Nous avons calculé au chapitre précédent sa moyenne E(Mn) = μ et sa variance σ²(Mn) = σ²/n.
Soit ε un nombre choisi arbitrairement aussi petit que l’on veut. En utilisant l’inégalité de Bienaymé-Tchebichef, on peut écrire que:
Prob{|Mn-μ| > ε} < σ²/(nε²)
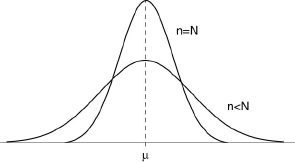
et, en posant σ²/(nε²) = η, on voit qu’étant donnés ε et η aussi petits qu’on le veut, il est possible de trouver un nombre N = σ²/(ηε²) tel que n ≥ N entraîne:
Prob{|Mn-μ| > ε} < η
C’est la loi des grands nombres que l’on peut encore énoncer ainsi: quand n augmente, la moyenne Mn converge en probabilité vers l’espérance mathématique de X
. Il est important de bien prendre conscience de la différence entre la notion de convergence classique et celle, toute nouvelle, de convergence en probabilité.
Dire que Mn tend au sens classique vers μ, ce serait dire qu’on peut déterminer n tel qu'étant donné ε aussi petit qu’on veut:
|Mn-μ|≤ ε
Dire qu’il y a convergence en probabilité, c’est dire que l’événement {|Mn-μ| ≤ ε} n’est pas certain, mais que sa probabilité peut être rendue aussi voisine de 1 qu’on le veut, à condition que n soit suffisamment grand:
Prob{|Mn-μ|≤ε} ≥ 1-η
On peut l’illustrer par la figure suivante: quand n augmente, la distribution de Mn se resserre autour de μ .
Estimation et Estimateur
Pour simplifier la suite de l’exposé, nous supposerons que la loi de référence à déterminer dépend d’un seul paramètre θ. Le problème se réduit donc à déterminer une fonction des observations: θ* (x1, x2, ... , xn), aussi voisine que possible de la valeur vraie θ qui est inconnue. On dit alors que θ* est une estimation de θ.
On peut utiliser, pour résoudre ce problème, la notion d’estimateur. Etant donné une variable aléatoire Tn (X1, X2, ... , Xn) fonction des variables aléatoires X1, X2, ... , Xn, on dit qu’elle constitue un estimateur de θ si:
- son espérance mathématique tend vers θ quand n augmente indéfiniment: E(Tn) →n→∞θ
- sa variance tend vers 0 quand n augmente indéfiniment: E[Tn-E(Tn)]² →n→∞0
Dans le cas particulier où E(Tn) = θ quel que soit n, l’estimateur Tn est dit sans biais.
Estimateur et Convergence en Probabilité
Pour éclairer la compréhension de la définition d’un estimateur, on peut la rapprocher de celle de la convergence en probabilité.
Un estimateur Tn est dit convergent, si Tn converge en probabilité vers θ, quand n augmente indéfiniment, c’est-à-dire si, étant donnés deux nombres ε et η aussi petits qu'on le veut, il est possible de déterminer un nombre N tel que n > N entraîne:
Prob{|Tn-θ| > ε} < η
On a l’important résultat: un estimateur Tn dont l’espérance mathématique tend vers θ et dont la variance tend vers 0, quand n augmente indéfiniment, est convergent
. La démonstration qui suit peut être omise.
D’après l’inégalité de Bienaymé-Tchebichef, on a la relation:
Prob{|Tn-E(Tn)| < ε/2} > 1-4(σ²(Tn))/ε²
et a fortiori:
Prob{|Tn-θ| < ε/2 + |θ-E(Tn)|} > 1-4(σ²(Tn))/ε²
Puisque E(Tn) converge vers θ au sens ordinaire de l’analyse, on peut trouver un nombre N1 tel que:
|E(Tn)-θ| < ε/2 pour n > N1
soit, pour une telle valeur de n:
Prob{|Tn-θ| < ε/2 + ε/2 } > 1-4(σ²(Tn))/ε²
Or, puisque σ² (Tn) tend vers 0 quand n augmente indéfiniment, on peut trouver un nombre N2 tel que:
σ²(Tn) < (ηε²)/4 pour n>N2
Par suite, pour n supérieur au plus grand des deux nombres N1 et N2 , on aura:
Prob{|Tn-θ|> ε} < η
Ce critère permet de définir l’efficacité d’un estimateur: un estimateur est d’autant plus efficace que sa variance est plus petite.
Intervalle de Confiance d’une Estimation
Il reste maintenant à définir la précision de l’estimation. Considérons, pour cela, la distribution de la variable aléatoire Tn . Si nous convenons de considérer comme négligeable un certain seuil de probabilité α, nous pouvons déterminer un intervalle [θ-ε1, θ+ε2] tel qu’il lui corresponde la probabilité (1-α).
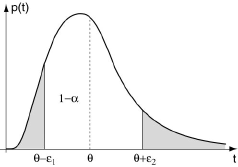
Il résulte de la définition même de cet intervalle que l’on a la probabilité (1 - α) d'observer l'évènement {θ-ε1 ≤ Tn ≤ θ+ε² }.
Cela étant, chaque fois que cette double inégalité est vérifiée, c’est-à-dire dans la proportion (1 - α) des cas, la double inégalité:
Tn-ε² ≤ θ ≤ Tn+ε1
est, elle aussi, vérifiée. L’intervalle [Tn-ε², Tn+ε1] est ainsi un intervalle aléatoire auquel peut être associée la probabilité (1 - α) de recouvrir la vraie valeur inconnue de θ:
Prob{ Tn-ε² ≤ θ ≤ Tn+ε1 } = 1-α
Si maintenant, nous observons les résultats de l’échantillon effectivement prélevé et calculons la valeur θ* de Tn pour cet échantillon, l’intervalle [θ*-ε², θ*+ε1] est appelé intervalle de confiance de l’estimation de θ, au seuil de probabilité (1 - α).
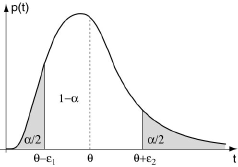
Remarquons qu’il y a une infinité de façons de répartir la probabilité α, dont l’une correspond à un intervalle minimal, mais qui n’est pas toujours facile à déterminer en pratique. C’est pourquoi on convient généralement de répartir α par moitié de part et d'autre de l’intervalle. Cette répartition donne lieu à l’intervalle minimum dans le cas particulier où la densité de probabilité est symétrique et décroît pour des valeurs qui s'éloignent de θ.
Estimation d’une Proportion
Considérons une population qui contient une proportion ϖ inconnue de pièces défectueuses. La variable aléatoire Kn, nombre de pièces défectueuses dans un échantillon de taille n, suit une loi binomiale de moyenne n ϖ et de variance n ϖ (1-ϖ). Si nous considérons maintenant la variable fréquence Kn/n , elle a pour moyenne ϖ et pour variance (ϖ(1-ϖ))/n.
Kn/n a donc les propriétés d’un estimateur sans biais de ϖ (E(Kn/n)=ϖ) et convergent (σ²(Kn/n) →n→∞0). Pour estimer ϖ, il suffit donc, ayant prélevé un échantillon de taille n dans la population, de calculer le nombre kn de pièces défectueuses puis:
ϖ* = kn/n
Pour déterminer l’intervalle de confiance, au risque α, de cette estimation, soient c1(ϖ) et c2(ϖ) les nombres tels que pour chaque valeur possible de ϖ:
α/2 ≤ ∑k=0c1 Cnk ϖk (1-ϖ)n-k et α/2 ≤ ∑k=c2∞ Cnk ϖk(1-ϖ)n-k
Il est alors possible de construire le graphe ci-dessous en portant ϖ en abscisse et c1(ϖ)/n ou c2(ϖ)/n en ordonnée. La surface comprise entre les deux courbes est ainsi le lieu des valeurs possibles de k/n pour l’ensemble des valeurs possibles de ϖ, lorsqu’on néglige le seuil de probabilité α.
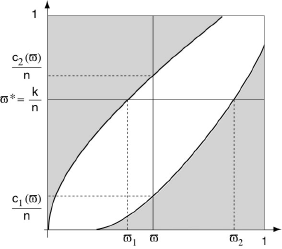
Lisant maintenant le graphique suivant l’horizontale d’ordonnée ϖ* = k/n , on peut immédiatement obtenir l’intervalle de confiance [ϖ1, ϖ2] correspondant à cette estimation.
Estimation d’une Moyenne
Etant donnée une population de moyenne μ inconnue et de variance σ² connue, soit Mn la variable aléatoire moyenne d’un échantillon de taille n. On a montré que E(Mn) = μ et σ² (Mn) = σ²/n . Mn constitue donc un estimateur sans biais et convergent de μ. Par conséquent, ayant prélevé un échantillon, sa moyenne est une estimation de μ:
m = μ*
Si ce résultat est absolument général et qu’il est, en particulier, indépendant de la forme analytique de la loi de probabilité suivie par les observations, la détermination d’un intervalle de confiance nécessite la connaissance de cette forme. Admettons qu’il s’agisse d’une loi normale, de variance σ² connue.
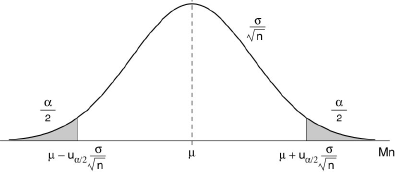
Il en résulte que Mn suit aussi une loi normale de moyenne μ et d’écart-type σ/√n . Etant donné un seuil de probabilité α, on peut écrire:
Prob{μ - uα/2 x σ/√n < Mn < μ + uα/2 x σ/√n } = 1-α
où uα/2 est lu dans la table de la loi normale réduite de telle façon que:
Prob{|U|> uα/2 } = α
L’intervalle de confiance de μ est donc:
μ* - uα/2 σ/√n < μ < μ* + uα/2 σ/√n
Bien souvent la variance σ² n’est pas connue. Nous verrons, dans la suite du chapitre, comment procéder dans ce cas. Notons que le théorème central limite permet de généraliser ces résultats à une loi de probabilité quelconque, mais à condition que n soit suffisamment grand (quelques dizaines en pratique).
Estimation d’une Variance
Soit une population quelconque de variance inconnue. Soit Sn² la variable aléatoire: variance d'un échantillon de taille n, qui s’écrit:
Sn² = 1/n ∑i=1n (Xi-Mn)²
où Mn désigne la variable aléatoire moyenne. On peut encore écrire:
Sn² = 1/n ∑i=1n [(Xi-μ)-(Mn-μ)]²
et, en développant le carré (moyenne des carrés moins carré de la moyenne):
Sn² = 1/n ∑i=1n (Xi-μ)²-(Mn-μ)²
Calculons, sous cette dernière forme, E(Sn²). Il vient, compte tenu de la linéarité de l'opérateur Espérance:
E(Sn²) = 1/n ∑i=1n E[(Xi-μ)²]-E[(Mn-μ)²]
et, en notant que E[(Xi-μ)²] et E[(Mn-μ)²] sont respectivement les variances de Xi et de Mn:
E(Sn²) = σ²-σ²/n = (n-1)/n σ²
On pourrait montrer, d’autre part, mais les calculs sont assez laborieux, que:
σ²(Sn²) = (n-1/n)² × μ4-σ4/n + 2(n-1)/n3 σ4
où μ4 désigne le moment centré d’ordre 4, E[(Xi-μ)4].
Il en résulte que Sn² est un estimateur convergent de σ², mais qu’il n’est pas sans biais. Le passage à un estimateur sans biais ne présente toutefois aucune difficulté. Il suffit de considérer la quantité: n/(n-1) Sn² dont l’espérance mathématique est:
E(n/(n-1) Sn²) = n/(n-1) E(Sn²) = σ²
Nous noterons, par la suite σ*² cette estimation sans biais de σ²:
σ*² = n/n-1 s² = 1/(n-1) x ∑i=1n (xi-m)²
qui est calculée par presque toutes les calculettes effectuant des calculs statistiques. Le calcul de l’intervalle de confiance, dans le cas d’une population normale, nécessite la connaissance préalable d’une nouvelle loi d’échantillonnage que nous allons établir maintenant.
2 - Intervalle de confiance de la variance inconnue d'une population normale
Loi du χ²
Soient U1, U2, ... , Uν, ν variables aléatoires indépendantes qui suivent des lois normales réduites. Posons:
χν² = U1² + U2² + ... + Uν²
La variable χν² suit une loi appelée loi du χ² (khi deux) à ν degrés de liberté. Nous allons établir la forme analytique de cette loi qui joue un rôle essentiel en statistique, et dont il faut retenir la définition, mais le calcul qui suit n’est, quant à lui, pas essentiel.
Nous nous proposons de déterminer la loi de probabilité de la variable χν² ; mais nous allons d'abord déterminer la loi de probabilité de la variable χν, c’est-à-dire que nous allons calculer la probabilité pour que χν se trouve compris dans l’intervalle [c, c+dc].
La probabilité pour qu’on ait à la fois:
u1 ≤ U1 < u1+du1 , u2 ≤ U2 < u2+du2, ... et uν ≤ Uν < uν+duν
s’écrit, U1, U2, ... , Uν étant indépendantes:
1/2√π e-u1²/2 du1 × ... × 1/2√π e-uν²/2 duν = 1/(2π)ν/2 e-1/2 (u1² + ... + uν²) du1 du2 ... duν
Ce résultat peut s’interpréter géométriquement de manière très simple. Considérons, dans l'espace à ν dimensions, le point P de coordonnées (U1, U2, ... , Uν). La probabilité pour que P tombe à l’intérieur d’un certain volume dv défini autour du point P est:
1/(2π)ν/2 e-1/2 OP⇀² dv
Dans ces conditions, la probabilité pour que la variable χν soit comprise entre les deux valeurs c et c+dc est égale à la probabilité pour que P tombe dans la région comprise entre les deux sphères de centre O et de rayons c et c+dc. Or la densité de probabilité est constante dans cette région et elle est égale à:
1/(2π)ν/2 e-c²/2
D’autre part, le volume de la sphère de centre O et de rayon c est de la forme k cν où k est une certaine constante, si bien que le volume compris entre les deux sphères de rayons c et c+dc est égal à: dv = k ν cν-1 dc. On obtient finalement:
Prob{c ≤ χν < c+dc} = kν/(2π)ν/2 c(ν-1) e-c²/2 dc
Pour obtenir, maintenant, la loi de probabilité de la variable χν², faisons le changement de variable x = c². On obtient:
Prob{x ≤ χν² < x+dx} = kν / 2.(2π)ν/2 x(ν/2-1) e-x/2 dx
qui définit la loi de probabilité cherchée, à la constante k près. Pour calculer cette constante, on peut écrire que: Prob{ χν² ≥ 0} = 1, soit:
kν / 2.(2π)ν/2 ∫0∞ x(ν/2-1) e-x/2 dx = 1
d’où finalement l’expression de la loi du χ²:
Prob{x ≤ χν² < x+dx} = (x(ν/2-1) e-x/2)/(∫0∞ x(ν/2-1) e-x/2dx)dx
Notons qu’on définit en mathématiques les fonctions Γ (gamma) dont les équations sont de la forme: Γ(a) = ∫0∞ xa-1 e-x dx, où a est une constante positive. L’intégrale au dénominateur de l’expression de la loi de probabilité du χ² peut alors s’écrire:
∫0∞ x(ν/2-1) e-x/2 dx = 2(ν/2) Γ(ν/2),
et on peut la calculer à partir des valeurs des fonctions Γ.
Il existe des tables de la loi du χ² qui donnent généralement, pour chaque valeur du nombre ν de degrés de liberté, la valeur x telle que: Prob{ χν² > x} = α, où α est une probabilité donnée: 1 %, 5 %, ... Il est par conséquent inutile de retenir la formule de la loi du χ² . Par contre, il est indispensable de connaître les propriétés suivantes de la loi du χ² .
Sommes de variables suivant des lois du χ²
Si χ1² et χ2² sont deux variables indépendantes qui suivent des lois du χ² respectivement à v1 et v2 degrés de liberté, leur somme (χ1² + χ2²) suit une loi du χ² à (v1 + v2) degrés de liberté. Cela résulte immédiatement de la définition de la loi du χ² .
Moyenne et variance d’une variable qui suit une loi du χ²
La moyenne d’une variable suivant une loi du χ² à ν degrés de liberté est égale à ν et sa variance est égale à 2ν. En effet, U étant une variable centrée réduite, sa variance est σ(U²) = E(U²)-[E(U)]² = 1 et, d’autre part, l’espérance d’une somme est égale à la somme des espérances, d’où:
E(χν²) = E(U1²)+ E(U2²) + ... + E(Uν²) = ν.
Pour calculer la variance, on sait que la variance d’une somme de variables indépendantes est égale à la somme des variances:
σ²(χν²) = σ²(U1²)+ σ²(U2²) + ... + σ²(Uν²) = ν σ²(U2)
et que la variance est égale à l’espérance du carré moins le carré de l’espérance:
σ²(U2) = E(U4) - [E(U2)]²
Enfin, on montre facilement, en intégrant par parties, que:
E(U4) = ∫-∞+∞ u4 e-u²/2 du = 3
σ² (χν²) = ν(3-1) = 2ν.
Loi de la variance d’un échantillon extrait d’une population normale dont l'écart-type est connu
Nous allons, en fait, chercher la loi de la quantité: ∑i=1n (Xi- Mn)² qui figure au numérateur de la variance et établir un résultat dont on pourra déduire immédiatement l'intervalle de confiance d'une variance. La démonstration peut être omise, mais les résultats suivants sont importants.
Etant donné un échantillon de taille n qui est extrait d’une population normale de variance égale à σ² , la variable aléatoire:
1/σ² ∑i=1n (Xi- Mn)²
suit une loi du χ² à (n-1) degrés de liberté. D’autre part, les variables Mn et ∑i=1n (Xi- Mn)² sont des variables indépendantes. Cette dernière propriété sera utilisée un peu plus loin.
Nous avons montré, au cours de ce chapitre, que l’on peut écrire:
∑i=1n (Xi- Mn)² = ∑i=1n Xi² - n Mn²
Soit alors P le point de coordonnées (X1, X2, ... , Xn), et soient (Y1, Y2, ... , Yn) ses nouvelles coordonnées après un changement de coordonnées orthonormales, que nous allons choisir tel que la coordonnée Yn soit justement égale à √n Mn. Dans ces conditions, ∑i=1n Xi² - n Mn² sera égal à ∑j=1n-1 Yi² , c’est-à-dire à la somme de (n-1) variables, dont nous allons montrer qu’elles sont indépendantes et qu’elles ont même variance σ² .
Ces conditions sont réalisées si l’axe des Yn est choisi passant par le vecteur unitaire dont toutes les coordonnées sont égales à 1/√n dans l’ancien système d’axes. Les nouvelles coordonnées de P s’écrivent:
Y1 = a11X1 + ... + ai1Xi + ... + an1 Xn ... Yj = a1j X1 + ... + aijXi + ... + a1j Xn ... Yn-1= a1n-1 X1 + ... + ain-1Xi + ... + ann-1 Xn Yn = 1/√n X1 + ... + 1/√n Xi + ... + 1/√n Xn
Les aij sont déterminés d’une infinité de façons par les relations:
a1j/√n + ... + aij/√n + ... + anj/√n = 0 a1i a1j + ... + aii aij + ... + ani a1j = 0 (a1j)² + ... + (aij)² + ... + (a1j)² = 1
Dans ces conditions, on montre facilement que les nouvelles variables Yj suivent des lois normales, indépendantes, centrées et d’écart-type σ puisque: E(Yj) = 0, E(Yj Yj') = 0 et E[(Yj)²] = σ² . On a, d’autre part: ∑j=1n Yj² = ∑i=1n Xi² puisqu’il s’agit d’un changement de coordonnées orthonormales. Comme Yn a été choisi de telle sorte que: Yn² =n Mn² , la variable:
∑i=1n (Xi- Mn)²/σ² = 1/σ² ∑i=1n Xi²-nMn²
peut s’exprimer en fonction des carrés de (n-1) variables normales, réduites, indépendantes:
∑i=1n (Xi- Mn)²/σ² = ∑j=1n-1 (Yj/σ)²
Elle suit donc une loi du χ² à (n-1) degrés de liberté. Et la variable Yn étant indépendante des variables Y1, ... , Yn-1, Mn et ∑i=1n (Xi- Mn)² sont des variables indépendantes.
Intervalle de confiance de la variance inconnue d'une population normale
Soit une population normale de variance σ² inconnue. La variable aléatoire 1/σ² ∑i=1n (Xi- Mn)² suit une loi du χ² à (n-1) degrés de liberté.
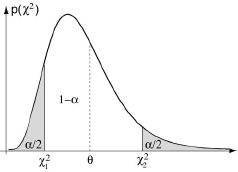
Se fixant un seuil de probabilité α, il est possible de déterminer l’intervalle [χ1², χ1²] tel que:
χ1² < 1/σ² ∑i=1n (Xi- Mn)² < χ2² avec la probabilité (1-α)
On en déduit l’intervalle de confiance pour σ², au risque α:
1/χ2² ∑i=1n (xi-m)² < σ² < 1/χ1² ∑i=1n (xi-m)²
ou encore:
ns²/χ2² < σ² < ns²/χ1²
3 - Intervalle de confiance de la moyenne inconnue d'une population normale d'écart-type inconnu
Loi de Student
Considérons (ν+1) variables aléatoires normales, réduites, indépendantes entre elles. Désignons les par U, U1 , ..., Ui , ..., Uν. La variable:
Tν = U / √(1/ν ∑i=1ν Ui²)
suit, par définition, une loi de Student à ν degrés de liberté. En remarquant que: ∑i=1ν Ui² suit une loi du χ² à ν degrés de liberté, on peut encore écrire Tν sous la forme:
Tν = U / √(χν²/ν)
où U et χν² sont des variables indépendantes qui suivent respectivement une loi normale réduite et une loi du χ² à ν degrés de liberté.
Pour ν = 1, la loi de Student s’identifie à une loi appelée la loi de Cauchy connue pour n’avoir ni moyenne, ni variance finies. On montre d’autre part que, lorsque ν → ∞, la loi de Student tend vers une loi normale réduite. Mais, pour ν fini, elle est plus étalée que la loi normale, sa variance (pour ν > 2) étant égale à ν/(ν-2) >1.
Il existe des tables donnant, pour un nombre de degrés de liberté donné, et pour des seuils de probabilité α fixés les valeurs t telles que: Prob{|T| > t} = α.
Loi de la moyenne d’un échantillon extrait d’une population normale d’écart-type inconnu
En notant σ*² l’estimateur sans biais de σ²:
σ*² = n/(n-1) s² = 1/(n-1) ∑i=1n (xi-m)²
nous allons montrer que la quantité:
t= m-μ / (σ*/√n)
est une réalisation d’une variable de Student à (n-1) degrés de liberté. En effet, la variable:
U= Mn-μ / (σ/√n)
suit une loi normale réduite puisque, si les Xi suivent une loi normale de moyenne μ et d'écart-type σ, Mn suit une loi normale de moyenne μ et écart-type σ/√n . D’autre part, la variable:
χn-12 = 1/σ² ∑i=1n (Xi-Mn)²
suit une loi du χ² à (n-1) degrés de liberté. Et ces deux variables sont indépendantes. Donc, la variable:
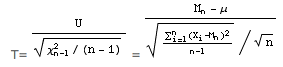
suit une loi de Student à (n-1) degrés de liberté.
Intervalle de confiance de la moyenne inconnue d’une population normale d’écart-type inconnu
Soit tα/2 la valeur lue dans la table de Student à (n-1) degrés de liberté, correspondant au risque α réparti symétriquement. Il résulte immédiatement de ce qui précède que l'intervalle de confiance, au risque α, de la moyenne inconnue μ (avec μ*=m, son estimation) est le suivant:
μ* - tα/2 σ*/√n < μ < μ* + tα/2 σ*/√n
expression dont la forme est la même que celle de l’intervalle de confiance établi dans le cas où l’écart-type σ est connu:
μ* - uα/2 σ/√n < μ < μ* + uα/2 σ/√n
Exercices
Vous pouvez entrer la réponse sous forme décimale (1.33), fractionnaire (4/3), ou encore passer une expression numérique: (5.5+2.5)/3/2
Il y a une tolérance sur la réponse de 0.001. Soyez précis, et ne confondez pas probabilité et pourcentage !
Exercice 1
- a) Définition d’une variable normale réduite à partir d’une variable normale quelconque ?
- b) Définition de la loi du χ² ?
- c) Définition de la loi de Student ?
- d) Quelle est la loi qui fait intervenir la moyenne d’un échantillon et les paramètres de la loi normale de référence ?
- e) Comment estimer l’écart-type de la loi de référence
- - si sa moyenne est connue,
- - si elle n’est pas connue ?
- f) Quelle est la loi qui fait intervenir la variance de la loi de référence et son estimation ?
- g) Que devient la loi précisée en d) si l’écart-type de la loi de référence n’est pas connu et qu’il faille l’estimer ?
L'exercice n'est pas simplement un pensum : il permet de fixer les idées à partir du cours. Son but est en particulier d'habituer l'étudiant à répondre à la question "Quelle type de loi utiliser selon que l'on connaît ou non la moyenne μ et/ou l'écart-type σ de la population de référence."
Exercice 2
On a mesuré la capacité (en microfarad) de 25 condensateurs et calculé la moyenne m = 2.086 et l’écart-type s = 0.079. Déterminer les intervalles de confiance de l'estimation de la moyenne μ de la population normale de référence, en choisissant un risque de 5 %, puis de 1 %. Est-il normal que le second soit plus grand que le premier ?
C'est un exercice de base : on calcule la moyenne de la population à partir de celle de l'échantillon, puis on l'encadre. Il est intéressant de remarquer comment évolue la taille de l'intervalle de confiance lorsque l'on diminue le risque.
La première étape consiste à déterminer un estimateur sans biais de l'écart-type de la population. Ensuite, on détermine quelle loi utiliser : ici, l'écart-type devant être estimé, on utilise Student. On peut alors déterminer la valeur d'une réalisation d'une variable de Student connaissant le nombre de degrés de liberté et le risque qu'on se donne. L'encadrement est fait selon la formule du cours.
Exercice 3
L'airbag (ou coussin gonflable) est un système de sécurité de plus en plus souvent installé dans les automobiles. Son gonflement est assuré par un dispositif pyrotechnique dont les caractéristiques importantes sont la moyenne et l’écart-type du délai entre la mise à feu et l'explosion. Lors de l’étude d’un certain type de dispositif d'allumage, les résultats des mesures, effectuées sur 10 exemplaires, ont été (en millisecondes): {28, 28, 31, 31, 33, 30, 31, 27, 32, 29}.
- Calculer, au risque 5%, l’intervalle de confiance de la moyenne du délai si on connaît l'écart-type de la population de référence et qu'il est égal à 2.
- Calculer ce même intervalle si on ne connaît pas l'écart-type de la population de référence.
- Calculer, au même risque, l’intervalle de confiance de la variance du délai, dont on déduira celui de l'écart-type dans le cas où on ne connaît pas l'écart-type de la population de référence.
On commence avec les valeurs données par calculer la moyenne m et l'écart-type s de l'échantillon.
a) si on connaît l'écart-type de la population, on utilise une loi normale
b) si on ne connaît pas l'écart-type, on doit l'estimer puis on utilisera une loi de Student (attention au nombre de degrés de liberté). On notera la largeur de l'intervalle à comparer avec celle trouvée en a)
c) pour encadrer l'écart-type, on utilise une loi du Khi2 (la aussi, attention au nombre de degrés de liberté)
Exercice 4
Les poids de pièces usinées en cuivre sont distribués normalement. Ayant prélevé 9 pièces, on a obtenu les poids suivants en grammes: 18.457; 18.434; 18.444; 18.461; 18.453; 18.447; 18.452; 18.440; 18.443.
Calculer m et s² , puis les intervalles de confiance au risque 5 % des estimations de la moyenne μ et de la variance σ².
Réponse
m =
s² =
L'exercice se résout comme le précédent. Il peut toutefois être intéressant d'effectuer un changement de variable pour déterminer moyenne et variance de l'échantillon. En effet, les variations de poids sont de l'ordre du 1/1000ème du poids des pièces. On vérifiera donc en calculant la variance selon la formule habituelle que celle-ci est faible, voire peut devenir négative pour peu qu'on arrondisse trop les valeurs intermédiaires ! On pourra ainsi poser y=1000(x-18.45) et calculer my et sy. Les règles d'algèbre de la moyenne et de la variance permettront alors d'obtenir mx et sx.
Exercice 5
Pour estimer la porosité d’un certain matériau, on a fait 10 mesures et calculé m = 94 et s² = 4. Déterminer l’intervalle de confiance au risque 5 % de l’estimation de μ. Combien faudrait il faire de mesures pour que cet intervalle soit de ± 0.5 seulement ?
La première partie n'introduit pas de difficultés nouvelles. Dans la seconde, on peut pour être précis raisonner en deux temps :
On calcule d'abord le nombre N d'observations nécessaires compte tenu de l'information disponible au moment du calcul (en termes de degrés de liberté), puis on affine en recalculant la valeur de la variable de Student pour le nombre de degrés de libertés correspondant à la valeur N. Que cela signifie t'il en termes de moyenne et écart-type de l'échantillon ?
Exercice 6
Un fabricant de piles électriques indique sur ses produits que la durée de vie moyenne de ses piles est de 200 heures. Une association de consommateurs prélève au hasard un échantillon de 100 piles et observe une durée de vie de 190 heures en moyenne avec un écart type de 30 heures. S'agit-il de publicité mensongère ?
On peut classiquement trouver un intervalle de confiance de la moyenne de la population pour un risque donné. On essaiera des risques de 5% et 1% pour se faire une idée.
Ensuite, on effectue le raisonnement inverse : quelle est la probabilité pour que la moyenne dépasse la valeur annoncée de 200 ? On conclut sur la véracité des propos du fabricant selon la probabilité trouvée.
Exercice 7
On a mesuré les durées de vie en heures de fonctionnement de 10 tubes électroniques du même type. On a obtenu les résultats suivants: 26; 31; 34; 40; 49; 60; 72; 85; 123; 179. Trouver une estimation sans biais du taux de défaillance, en admettant le modèle du processus de Poisson.
Réponse
pannes par heure pour un tube électronique
Exercice difficile, mais le raisonnement se retrouve dans différents domaines oùdes phénomènes aléatoires se produisent, par exemple en physique statistique.
On doit d'abord déterminer quelle est la probabilité que le dernier tube soit défaillant entre t et t+dt. Pour cela, il faut que n-1 tubes soient défaillants entre t=0 et t ET QUE un tube soit défaillant entre et t+dt
On aura ainsi une densité de probabilité f(t).dt, et on pourra alors calculer espérance et écart-type en écrivant que l'espérance est l'intégrale de 0 à l'infini de t.f(t).dt. On en déduira l'estimateur sans biais λ *.
Le calcul de l'intervalle de confiance nécessite d'intégrer la courbe de densité de probabilité et de chercher les valeurs correspondant à un risque de 5% réparti symétriquement. Ceci est facile avec Mathematica.